

Crisp Clustering#
This module provides a few additional clustering methods (Paasche and Eberle, 2009). It does not use algorithms from scikit-learn. The clustering is unsupervised, meaning that a multiple band dataset is supplied, and regions of the dataset is automatically grouped into classes.
Different ways of defining these classes are available. The simplest is k-means where the classes are circular or spherical in shape. In advanced k-means the classes can be ellipsoids, but they must be parallel to each other, while in w-means, they can be ellipsoids and they don’t have to be parallel to each other.
The options available for Crisp Clustering are:
Cluster Algorithm - This can be k-means, advanced k-means or w-means.
Minimum Clusters - Clustering can be done for a specific number of clusters or for a range of clusters. This option sets the minimum number of clusters that will be generated.
Maximum Clusters - The maximum number in the range of clusters that will be generated. For example, if the minimum number of clusters is 5, and the maximum number of clusters is 7, then 3 interpretations are produced, namely one with 5 classes, one with 6 classes and one with 7 classes.
Maximum iterations - Maximum number of iterations to use when generating a solution.
Terminate if relative change is less than - Threshold for termination.
Repeated runs - Run the algorithm a number of times to ensure robustness with regards to the initial guess.
Constrain cluster shape (w-means only) - 0 is unconstrained, 1 is spherical.
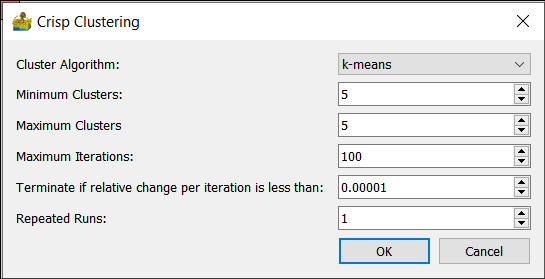
Crisp Clustering options.#
References#
Paasche, H., Eberle, D.G. 2009. Rapid integration of large airborne geophysical data suites using a fuzzy partitioning cluster algorithm: a tool for geological mapping and mineral exploration targeting. Exploration Geophysics, 40, 277-287.